uu加速器挂VPN费流量吗


重点一览:随着现代数据技术体系的发展,数据驱动已经成为企业管理不可或缺的一部分,数据遍布在企业内部的每一个角落。每个企业积累的海量的大数据,但真正发挥效能的数据微乎其微,形成了大量的“沉睡”数据。而企业内部的数据用户,从数据分析师到市场营销人员再到销售人员,每个员工现在都在使用数驱动业务,形成新的数据用户社区(Data Community)。
一方面,海量的数据在沉睡,另一方面,大量用户需求涌现,如今不足的数据计算资源和 BI 团队人力资源对这些不断增长的期望不堪重负。
新时代来临,结合Dev-Ops, New DataStack, DataFebric等诸多理念,全球企业开始采用最新的DataOps框架解决新时代的“数据蜘蛛网”问题。
白鲸开源 WhaleStudio 套件中的 WhaleScheduler 作为一款企业统一的云原生可视化大数据工作流调度平台,旨在帮助企业解决内部多数据源、多数据系统复杂的数据集成,持续开发、持续部署、数据捕获、数据打通等一系列问题。
WhaleScheduler具备可靠性、可扩展性、易用性、灵活性、可视化和安全性等特性,拥有完善的调度能力、数据处理能力、集群管理能力、数据可视化能力、监控和报警能力,以及安全管理能力,能够在复杂的生产环境中针对行业客户增加企业级产品功能并加强系统安全与稳定性,支持数据库、云、大数据、AI组件等数十种系统的任务调度,助力企业数据消费者、数据探索者、数据分析家、数据科学家,以及数据客户/供应商提高调度效率,降低生产成本。
为了降低数据调度系统的使用难度,使数据分析师等业务部门的人员无需代码背景也可以无门槛的进行数据开发和操作调度作业,WhaleScheduler 2.4.5 接入了 WhaleStudio 新增重要模块——WhaleGPT 的 AI 助手,可以辅助业务人员直接完成数据业务脚本开发,让他们更关注业务本身,而不是代码。
查询功能操作帮助,通过询问功能名称可以返回该功能的上手指南,部分功能提供跳转链接至指定操作界面;
通过对话提出需求让 GPT 生成 SQL 代码,在对话中将自己的需求描述出来,如写查询某某数据的 SQL,返回该需求的 SQL 代码。
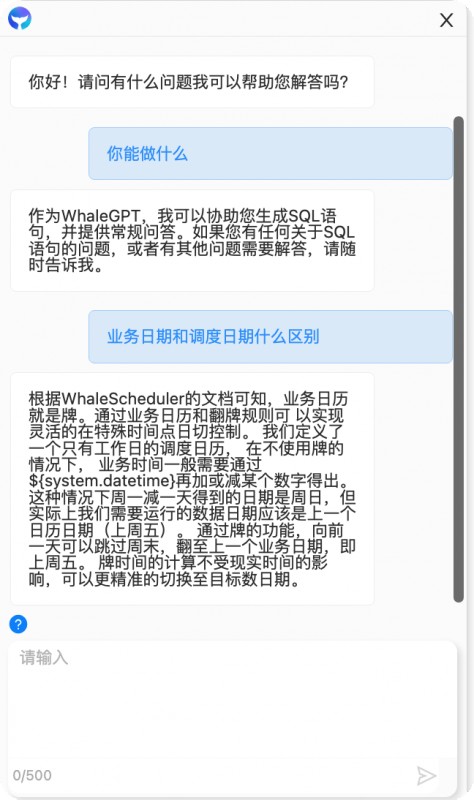

WhaleGPT 自带的大模型能力让企业可以快速训练私有化模型,普通程序员用半天时间就具备训练私有化大模型的能力,让大模型帮助客户更了解自己的业务,加强数据安全,跨越大模型与现有系统数据的鸿沟。
随着越来越多的数据库出现,数据分散、数据不一致、数据安全性等问题越来越突出,数据兼容性的问题(数据格式、数据结构、数据类型不兼容等)也变得更加复杂。
WhaleScheduler 有更多的数据源支持可以提供更全面、准确的数据,从而提高数据分析和决策的质量。同时,对于某些特定业务需要不同类型的数据源来支持的需求,WhaleScheduler 也能轻松应对。

同时,WhaleScheduler 全面支持云原生,为了帮助企业更好地适应大数据和云原生大时代下的数据处理与治理,我们对更多云厂商的相关数据库进行了支持:
信创(信息技术应用创新)是数据安全、网络安全的基础,也是“新基建”的重要内容,推动国家的核心技术必须实现自主可控。信创是目前国内的一项战略,也是当今形势下国内经济发展的新动能。
为解决本质安全的问题,助力企业自主可控地完成经济数字化转型、提升产业链发展,WhaleScheduler 2.4.5 版本对多个国产系统环境进行了适配,保障企业数据安全,包括:

WhaleScheduler 自诞生以来就将安全问题作为产品管理的关键指标,为了提高产品安全性,WhaleScheduler 2.4.5 优化多项安全措施:
支持使用 SSL 证书访问数据源、支持自动刷新 HDFS 服务认证、支持 zk 的 Kerberos 认证、Hive 数据源支持 keytab 配置、配置文件密码加密(jaspyt 加密)。
为了优化产品的使用习惯,WhaleScheduler 2.4.5 对首页、DAG、错误提示框等进行了优化,方便客户更加无边界地试用产品。
工作流逻辑任务新增 Dynamic 动态任务组件:在工作流逻辑组件中新增动态任务组件,使用动态任务组件后工作流可以在运行中根据每次输入参数变量的变化动态的生成调度实例。这对于需要针对不同的数据通过同样的脚本进行处理的用户来说,不再需要重复设置多个工作流,也不需要事先估算需要运行的实例数量,如机器学习模型多参数调参训练的场景。针对同类多样的数据调度,动态任务组件可以大批量的同时执行,大大提高了数据处理的效率。
基线告警:某些任务的数据需要在指定时间点之前完成,由于前置任务拖延,导致最后的任务不能在规定的时间点完成,需要提前预警并人工介入处理,因此需要提前预判任务是否有延误风险以提供处理的时间空间。关键调度任务可以通过设置基线进行监控,当存在未能承诺时间内完成的风险时及时给负责人进行告警提醒,以保障业务的正常运转。
支持自定义任务组件:当前工作流内不支持的任务类型,用户可以通过提供该组件jar包并在配置文件中设置需要配置的任务参数项,即可在工作流内新增该任务类型组件进行调度作业使用了。
影响分析支持展示工作流实例、任务实例的血缘,并支持运行操作:工作流实例、任务实例维度的调度血缘展示,同时可以在影响分析中直接对工作流和任务执行运行相关的操作。任务依赖是调度作业处理中的核心场景。尤其是企业规模较大业务涉及面更广时,其数据处理流程日益复杂。在调度作业中往往面临着庞大的调度依赖,一旦当其中某一个节点出现数据错误,排查问题变得十分困难,需要一个一个的检查依赖项并向上溯源。实例级的影响分析正是为了解决这一问题诞生的,使调度作业的运维工作变得更为简单和高效。在工作流/任务的运行实例的影响分析中,可以清晰地看到上有依赖的实例,并支持继续向上或拓展溯源。一旦找到了问题源头,经过处理后,可以在影响分析中直接执行相关的人工干预操作。
IDE 支持通过资源中心引入 SQL 脚本:除了脚本文件和 jar 之外,用户还可以可以直接在任务脚本里导入本地/git 上的 SQL 脚本。在任务中无需重复编写任务脚本uu加速器挂VPN费流量吗,可以将已经开发好的任务脚本上传至资源中心,或者通过资源中心引用 git 仓库中的脚本代码,或在资源中心中直接开发或共享的脚本文件,直接导入任务脚本中。
跨项目批量运维工作流:项目运维人员通常需要同时运维多个项目作业,反复地切换项目查看工作流和任务运行实例进行维护,影响使用体验。新增了跨项目的功能后,用户可以在统一视角,查看和处理自己权限范围内的所有调度业务了,简化了用户操作的同时提高了运维效率。
根据此前客户反馈权限功能的限制导致的不便,WhaleScheduler 2.4.5 进行了权限功能的改造,以便客户进行权限管理。
新版本中,客户可以按照项目来隔离角色权限,分为项目管理员、项目运维、项目开发、项目访客角色,结合资源管理给与不同人员不同权限。
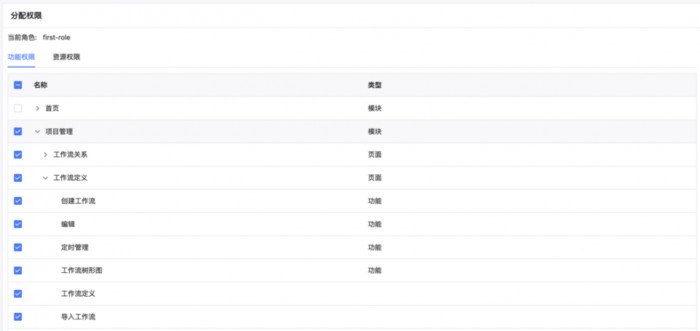
此外,新版本还增强了导入、导出功能。如果不采用自动化的 CI/CD 流程,WhaleScheduler 支持跨环境打包部署,主要用于工作的流的迁移工作,从环境 A 中导出(导入)到环境 B 中,通过该功能进行快速打包或数据备份。
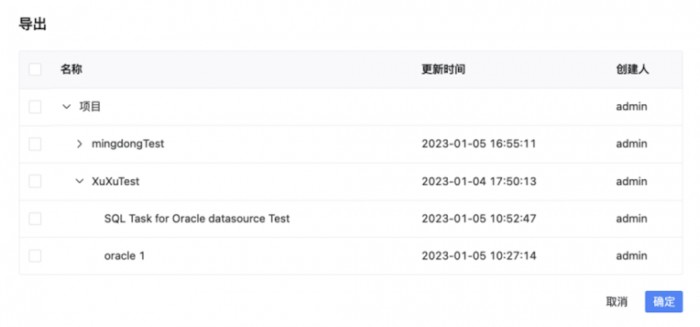
WhaleScheduler 此次版本升级将提高对用户的支持能力,更好地赋能企业云化的数据处理和调度、数据快速获取及企业整体云化数据资产的管理问题,协助完成企业数字化升级的整体目标。
白鲸开源一直致力于为用户提供更好的产品和服务,未来也将继续努力提升用户体验和满意度,不断提升产品性能、改进用户界面、增强数据安全性、提供更多功能,更多版本升级信息。
